
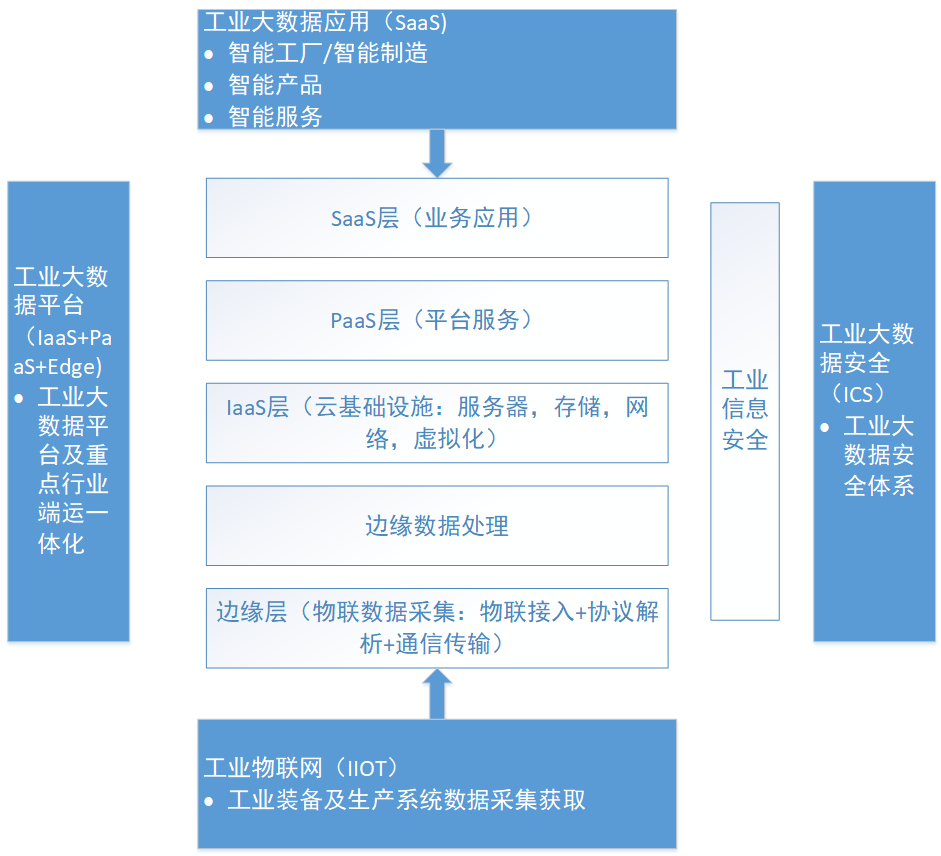
Industrial Big Data
Provide flexible and diverse data loading and scheduling capabilities for various real-time and batch industrial data generated during production, manufacturing, and operation stages; support diverse, high-performance, and expandable storage capabilities; establish multi-dimensional, diversified data retrieval and metadata Data services and APIs provide great data acquisition, analysis and processing capabilities for upper-level real-time monitoring and analysis, fault warning, and analysis and application establishment.
Data loading and scheduling:
For all kinds of real-time data, structured and unstructured data, it provides a flexible ingestion and scheduling mechanism, supports parallel scheduling loading and online conversion, and provides flexible data management and cleaning capabilities.
Data cleaning capability:
It is capable of processing multiple data sources such as streaming data, historical batch data, and unstructured data. Provide complete data governance capability support: data conversion, data standardization, data verification, etc. Real-time data can achieve back pressure and replenishment to maintain stable data intake.
Data management capabilities:
Provide full life cycle data governance and control, including data processing, data quality management, data security management, complete the cleaning, conversion, loading of access data, repair of problem data, simulation of missing data, and establish unified data access control mechanism.
Device metadata management:
Describe various objects, sources, attributes, and associations of assets, build data management for the entire life cycle of assets, provide standard data services for upper-level industrial Internet applications through open and secure interfaces, and realize true data sharing.
Safe and open access interface:
Provides a RESTFul API interface, supports different applications to access the metadata model of the digital twin through secure authorization, and provides a unified data change and release mechanism.
High-performance time series database:
It is used to store time-tagged IoT sensor data, provide high-performance writes and millisecond-level queries up to a single node's millions of levels, and support aggregation based on time granularity.
■ High performance: Supports continuous writing and millisecond-level queries of millions of data points per second on a single node.
■ Distributed: Support horizontal expansion, support higher writing, query performance and massive storage.
■ Multiple loading: support streaming loading and file loading methods.
■ Convenient query capabilities: with load and search, support thousands of concurrent queries, support SQL and Json two query languages, support multi-time granular aggregation.
■ High availability: Distributed query, load and storage nodes are provided, and the failure of a single node does not affect the operation of other nodes.



Comment